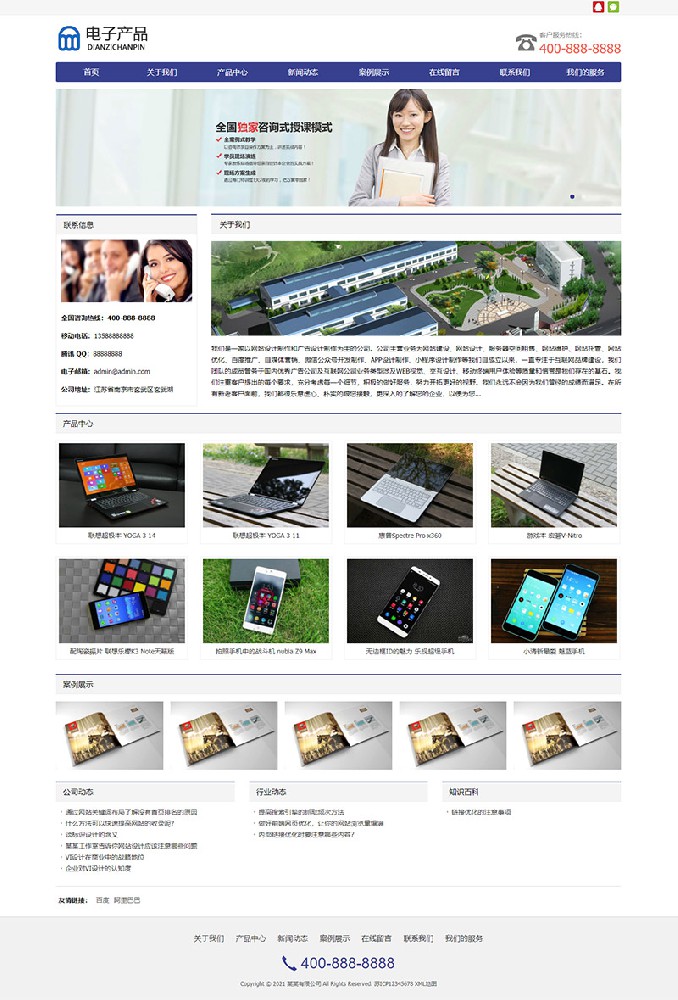
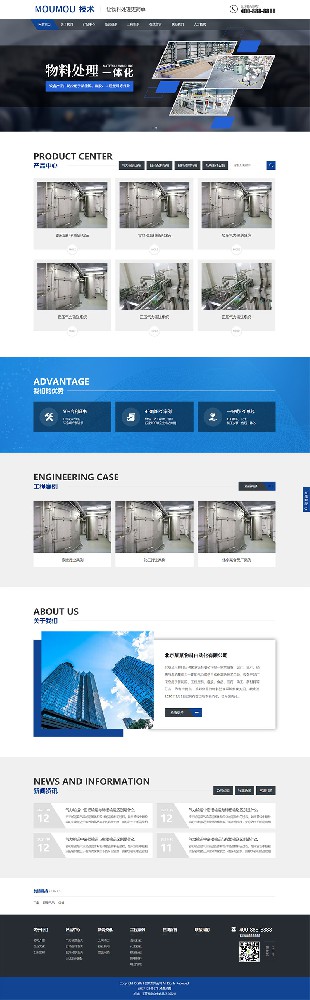
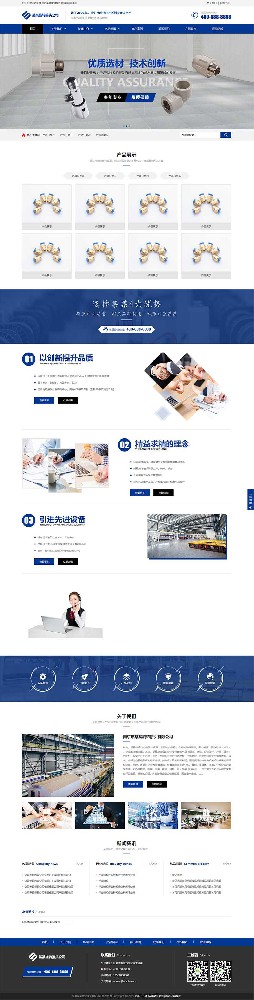
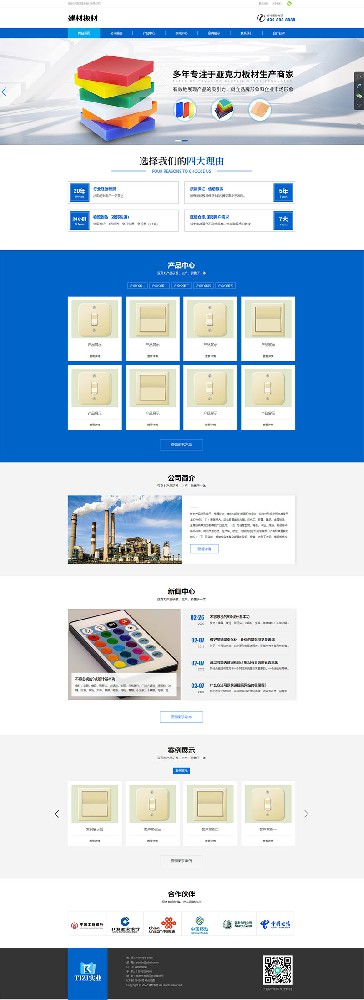
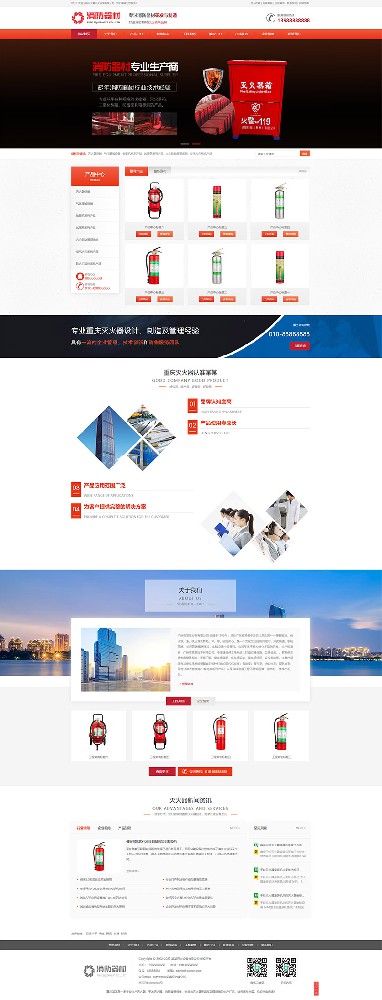
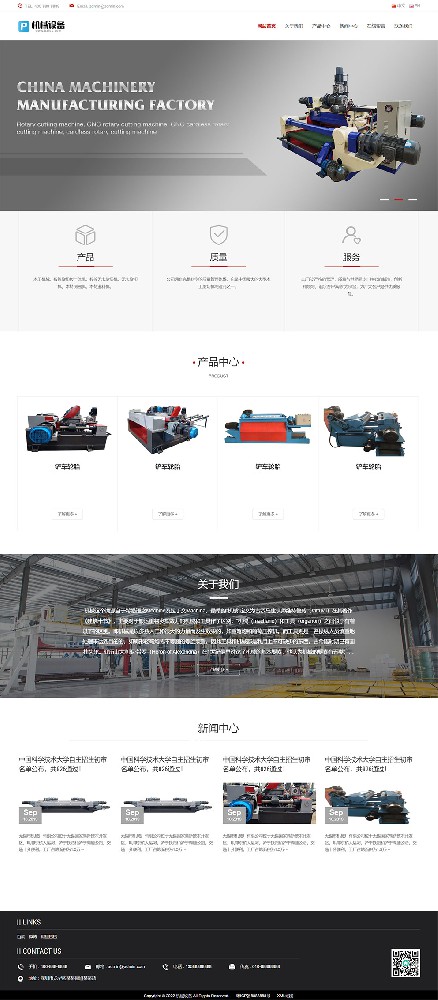
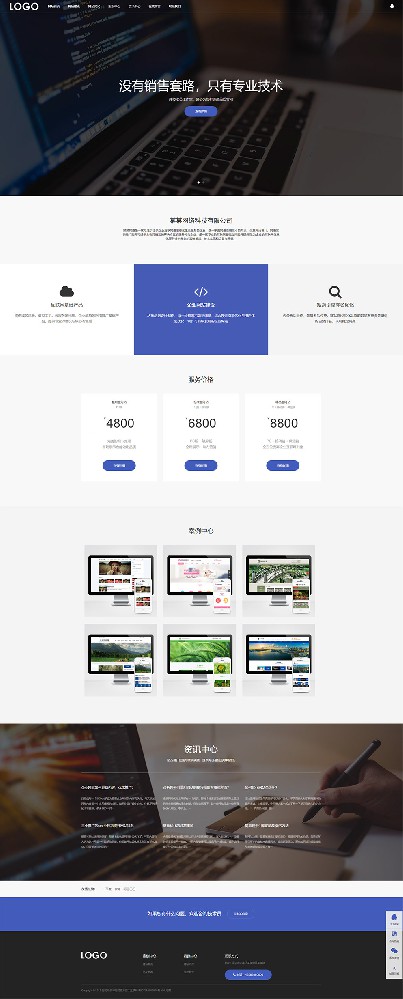
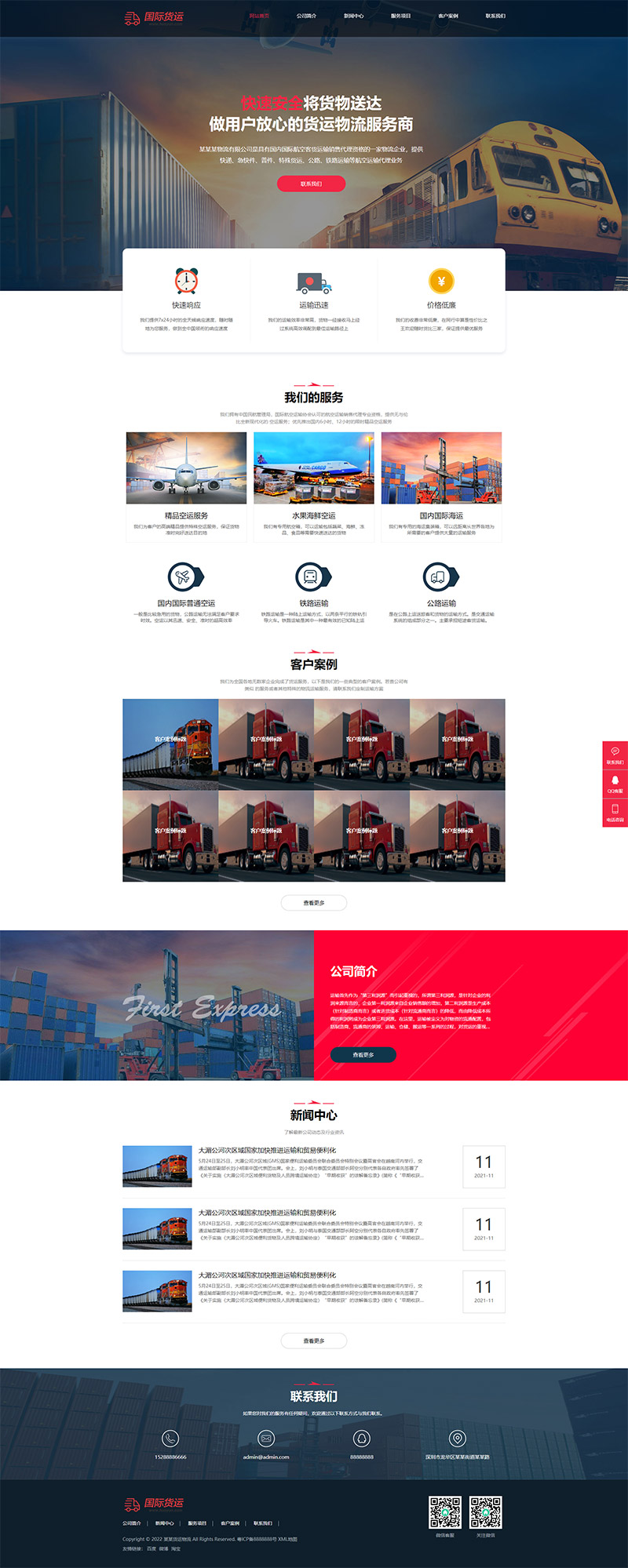
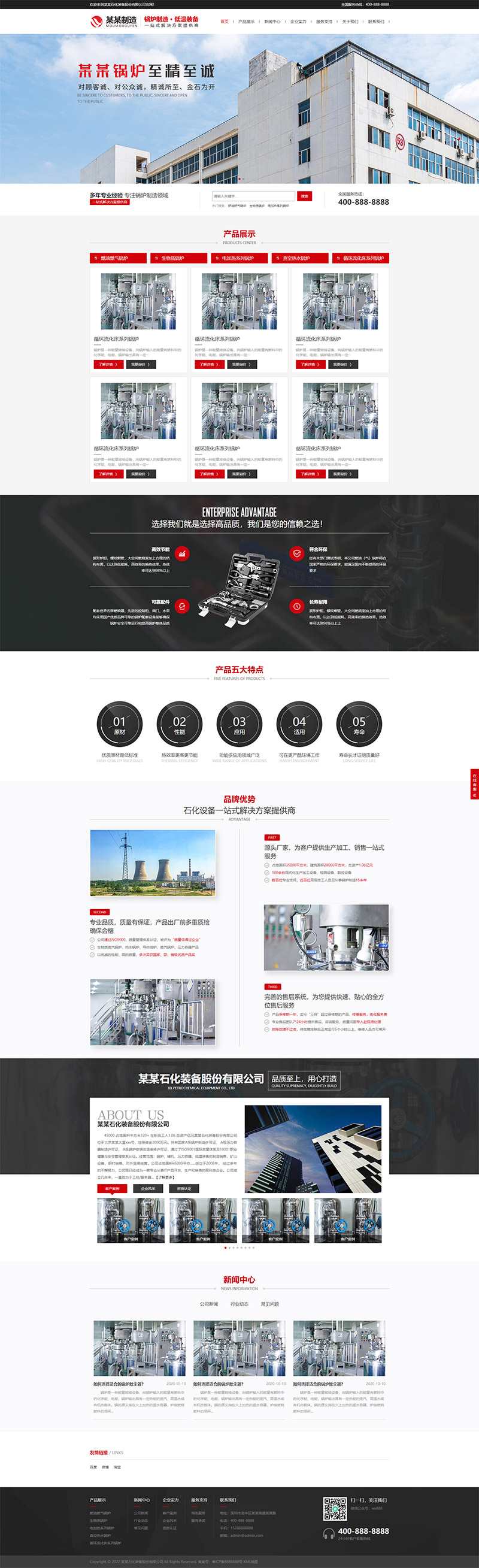
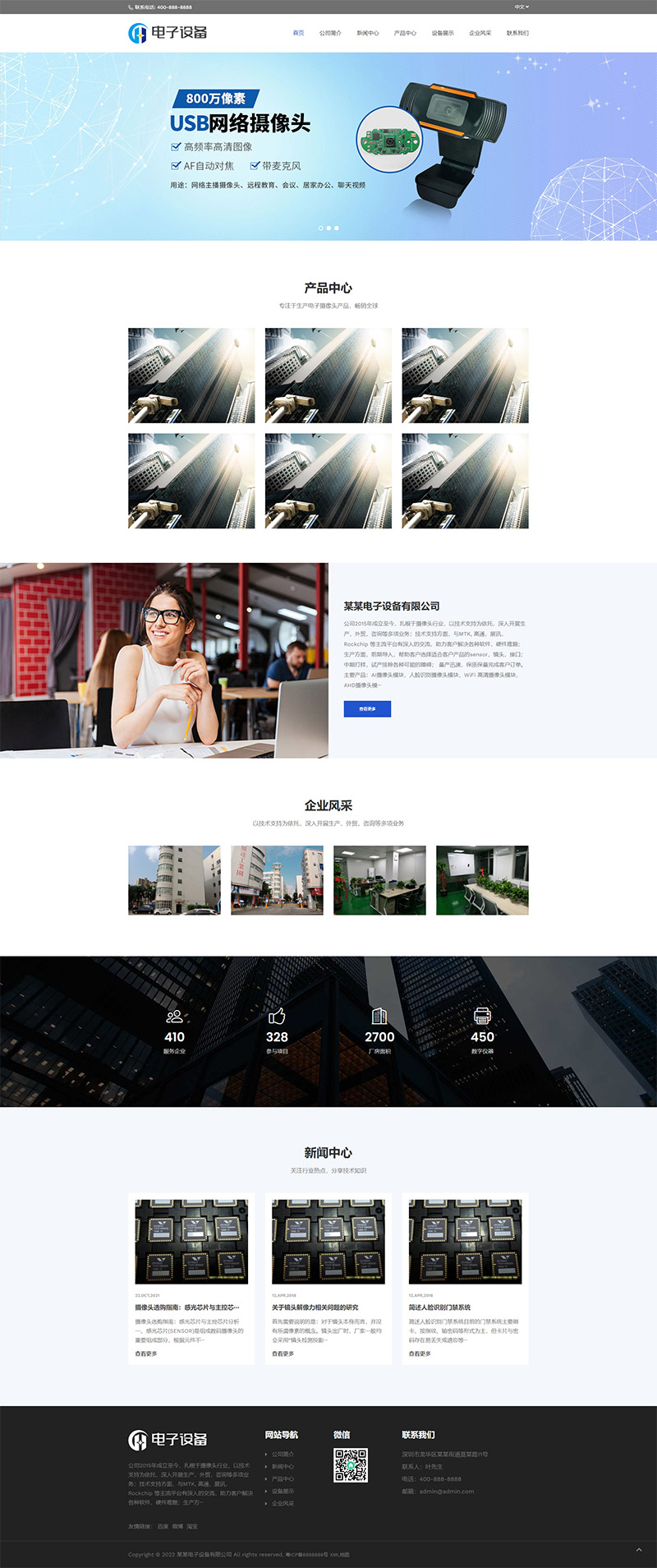
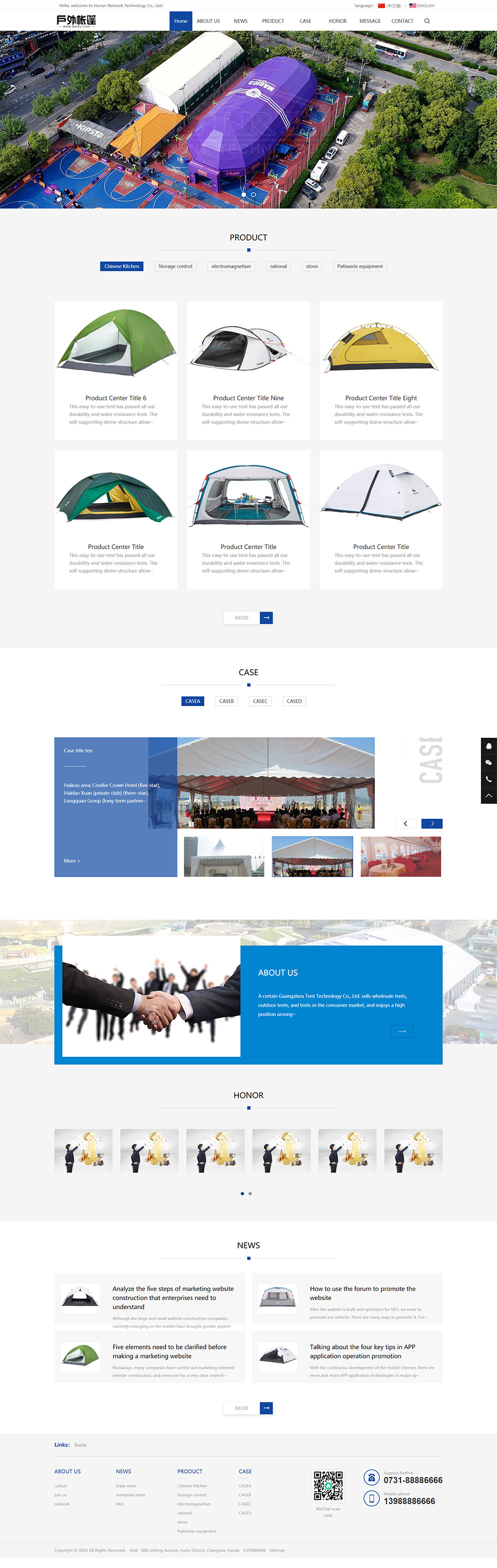
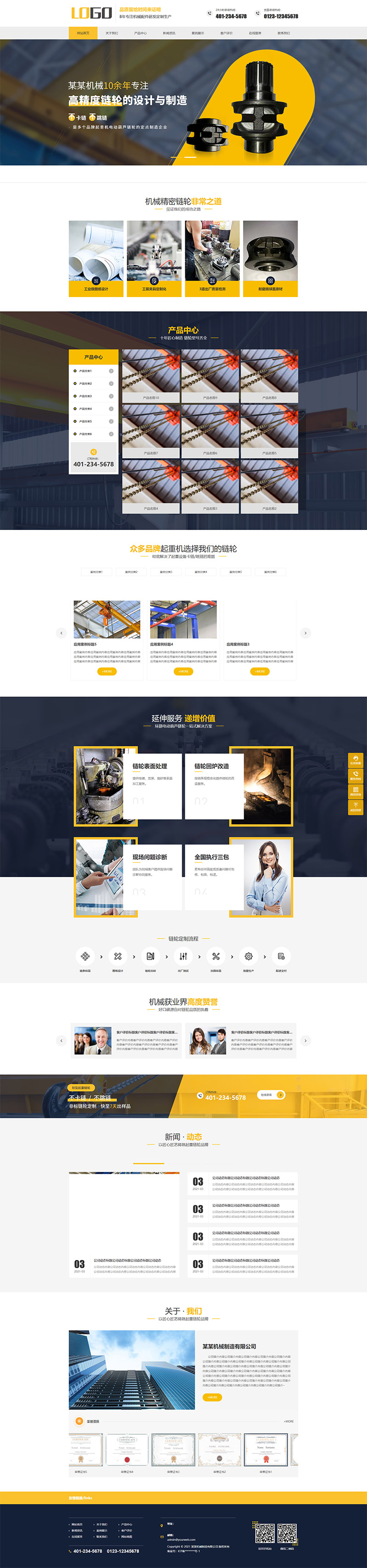
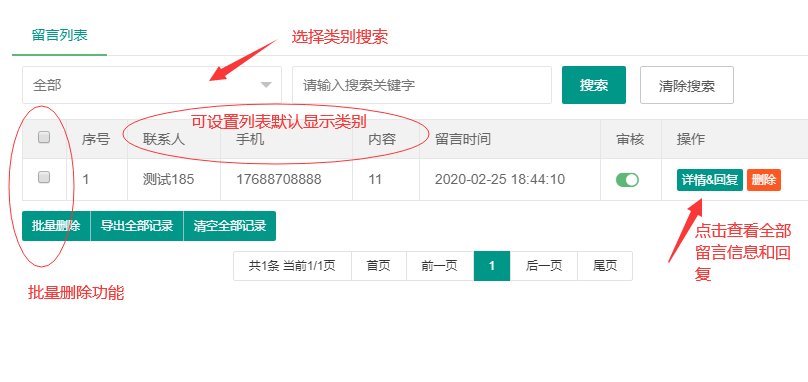
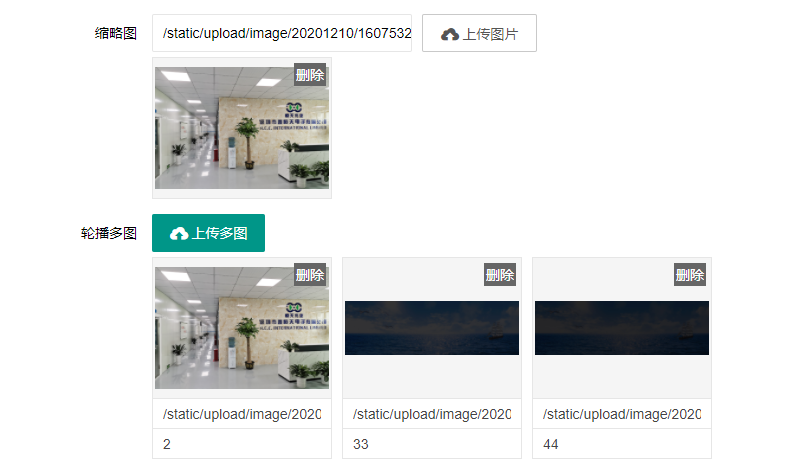
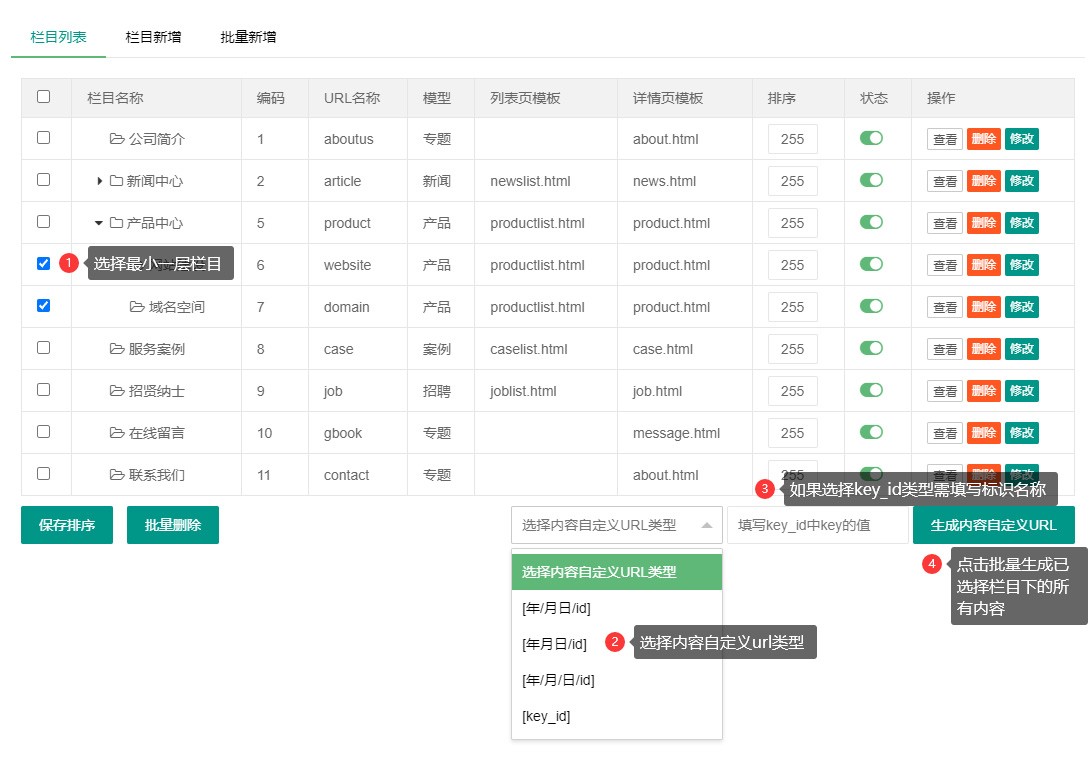
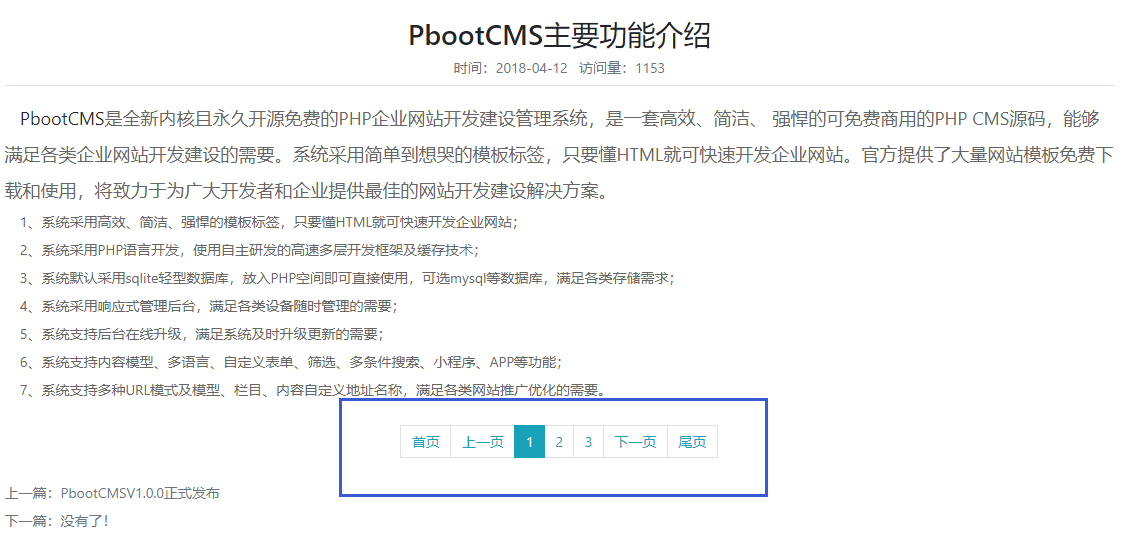
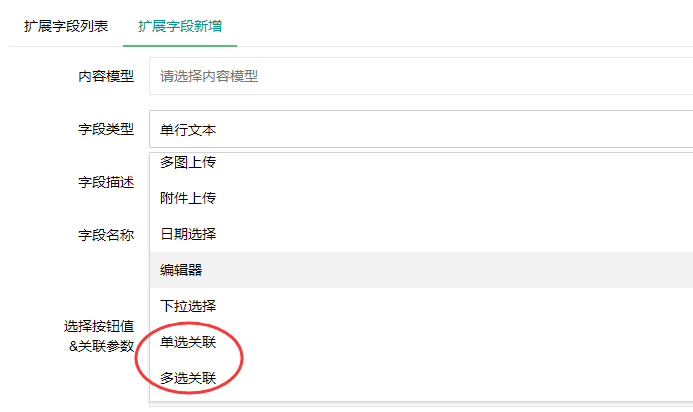
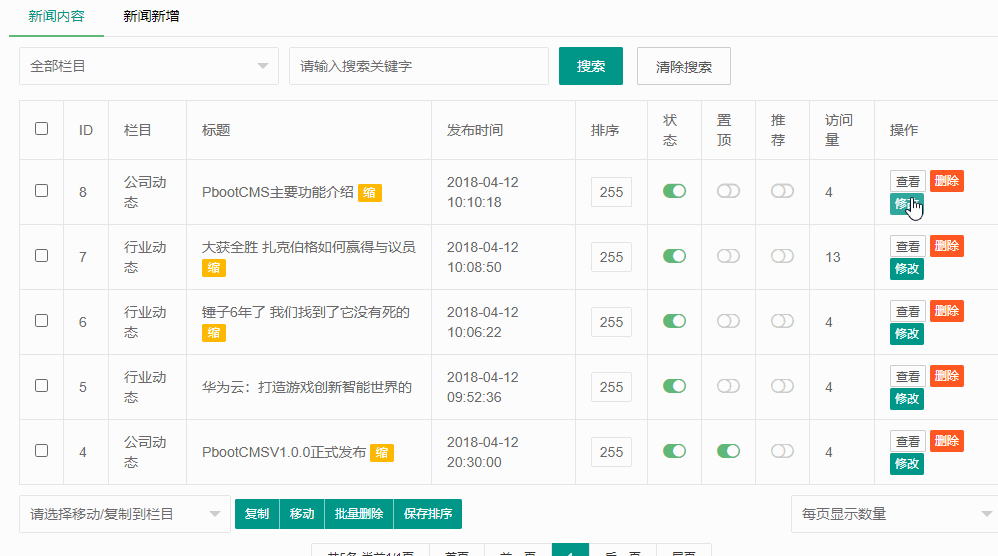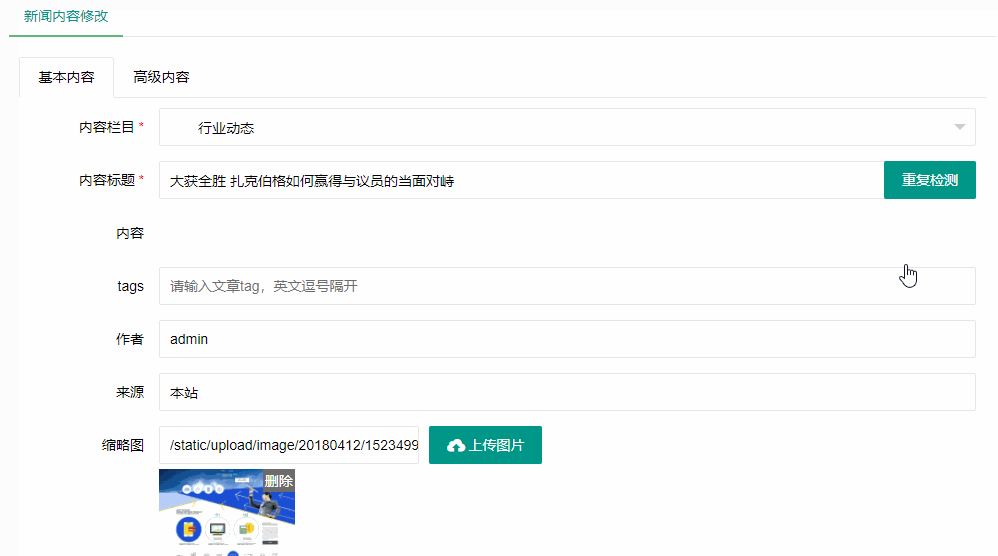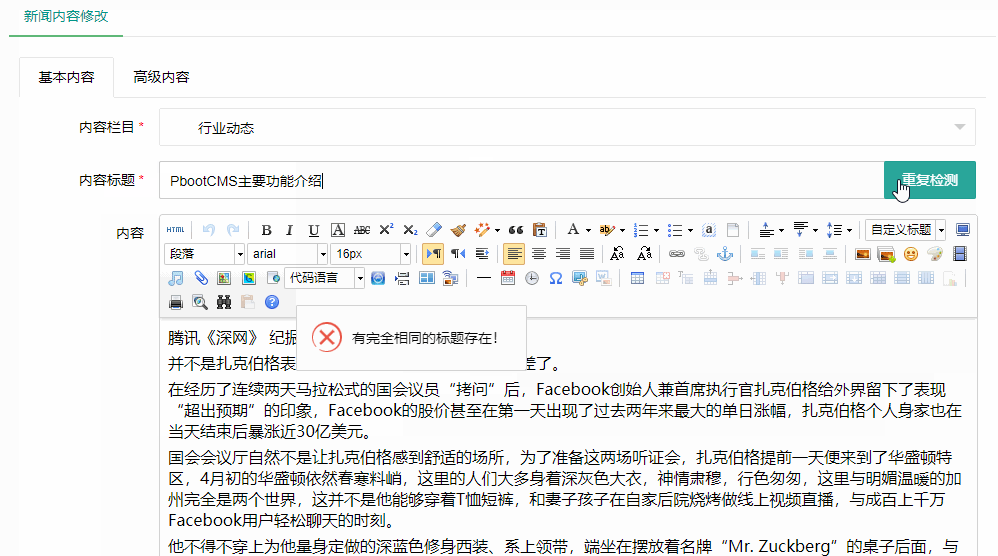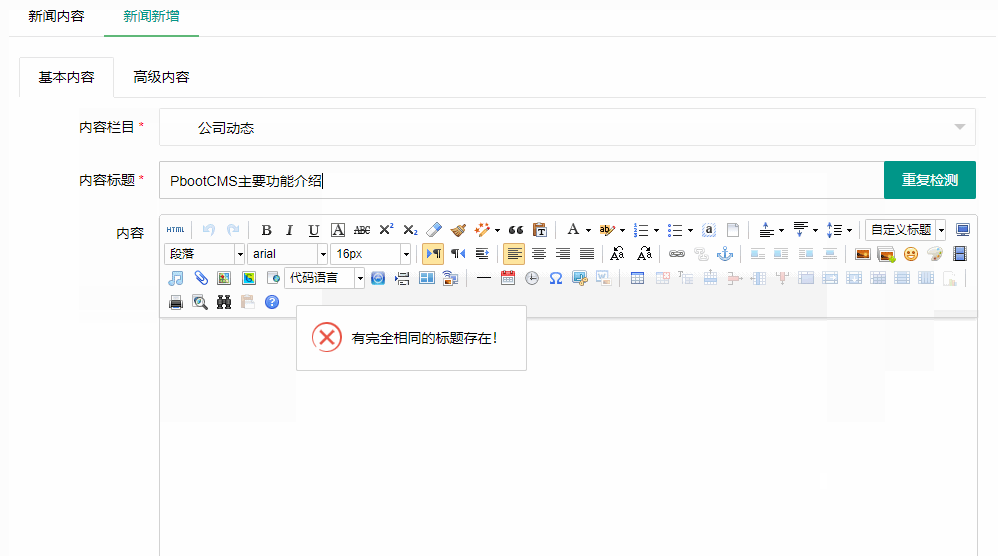
编号:113 #2023-04-26 22:05:00 299.00 pbootcms后台留言表单管理增强 插件介绍 ··· 编号:112 #2023-04-26 22:03:58 299.00 pbootcms新增多图字段实现自定义名称 ··· 编号:111 #2023-04-26 22:02:38 299.00 pbootcms定制url服务包 针对各种老网站转pbootcms··· 编号:110 #2023-04-26 22:01:10 299.00 pbootcms文章内容分页(基础版) &··· 编号:109 #2023-04-26 22:00:15 299.00 pbootcms提取content字段到独立表ay_content_data 针对pbootcms站点数据达到5W以上,提取content字段到新··· 编号:108 #2023-04-26 21:59:20 299.00 pbootcms多语言目录名方式切换 <··· 编号:52 #2023-04-26 20:09:28 299.00 pbootcms增加关联扩展字段 适配版本:3x以上 2023-04-26 20:09:28 编号:51 #2023-04-26 20:08:59 299.00 pbootcms标题重复自动检测功能 适配版本:3x以上 2023-04-26 20:08:59 编号:50 #2023-04-26 20:08:29 299.00 pbootcms留言表单手机短信验证(阿里云短信) <··· 编号:49 #2023-04-26 20:08:00 299.00 PbootCMS后台TAG标签管理插件 适配版本:3x以上 2023-04-26 20:08:00 查看更多 建站教程 > 1php里error_reporting() 的分析 2正则 的 分组语法(又叫 捕获 和 断言/零宽断言 ) 3百度统计免登陆查看数据的方法 4点击网页上QQ提示对方QQ在线状态”服务尚未启用 5仿站专家告诉你,做网站有哪些账号密码需要管理? 6未备案域名怎么使用国内cdn(七牛云)加速网站? 7没买虚拟主机或云服务器可以在阿里云备案吗? 8FlashFXP连接宝塔ftp提示“列表错误”怎么办 9解决网站在宝塔面板偶尔出现CPU100%的情况 10用PbootCMS做个网站要多少钱? 实用代码 > 1pbootcms在线升级后伪静态分页url变成?page=xx问题 2PbootCMS常用if判断语句 3pbootcms提示:登录失败:表单提交校验失败,请刷新后重试! 4西部数码虚拟主机上pbootcms使用注意(邮件通知、非法字符) 5pbootcms新增扩展标签实现单独手机端详情判断 6pbootcms3.2.2导入sql失败报错问题处理 7PC网站缩小在手机上显示的一条代码 8百度地图API调用时在网站上不显示原因 9jquery点击按钮复制内容代码(兼容PC、手机端) 10带/index.php的主域名301重定向到默认主域名 cms教程 > 1巧用伪静态让虚拟主机支持域名绑定到子目录 2pbootcms授权码免费获取(通过小程序获取) 3适合PbootCMS的阿里云短信发送类 4pbootcms列表页排序切换(时间/浏览量/推荐...) 5pbootcms去除ueditor编辑器上传图片自动添加的title和alt属性 6pbootcms后台编辑器插入视频无法播放怎么办 7pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 8pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 9pbootcms基本使用教程(快速入门视频) 10如何将pbootcms手机网页封装成微信小程序 网站seo > 1pbootcms2.0针对SEO优化之扁平化目录结构 2网站文章如何打造seo高质量伪原创? 3新站SEO优化该从何入手 4百度统计中出现垃圾网站被恶意刷关键词的解决办法 5网站被镜像的影响及解决方案 6百度快照显示网站图片或者公司LOGO怎么做? 72023年了为什么还有人做SEO? 8企业建站要注意这些细节,流量翻倍不是梦 9网站快排套路到底有多深? 10网站SEO文章双标题是什么?SEO双标题作用 不要把时间用来造轮子,这里有的你拿走,保留精力用来创造! 目前为止共有 2803 位优秀的站长加入! 立即加入vip 百元建站活动 QQ 客服在线 周一至周日 11:00-23:00 PBHTML团队为您服务 点击添加好友后咨询 微信 扫一扫添加客服微信 Q群 登录 注册 我已阅读并同意 《用户注册协议》 活动公告 本站全新品牌升级已于2022.12.28正式上线!限时特惠活动:终身VIP原价298元,现价198元!活动日期:2022.12.28 ~ 2023.12.30终身VIP特权将会逐步增加,早加入早受益!我们的目标:做最干净的模板,无内置广告链接。
编号:112 #2023-04-26 22:03:58 299.00 pbootcms新增多图字段实现自定义名称 ··· 编号:111 #2023-04-26 22:02:38 299.00 pbootcms定制url服务包 针对各种老网站转pbootcms··· 编号:110 #2023-04-26 22:01:10 299.00 pbootcms文章内容分页(基础版) &··· 编号:109 #2023-04-26 22:00:15 299.00 pbootcms提取content字段到独立表ay_content_data 针对pbootcms站点数据达到5W以上,提取content字段到新··· 编号:108 #2023-04-26 21:59:20 299.00 pbootcms多语言目录名方式切换 <··· 编号:52 #2023-04-26 20:09:28 299.00 pbootcms增加关联扩展字段 适配版本:3x以上 2023-04-26 20:09:28 编号:51 #2023-04-26 20:08:59 299.00 pbootcms标题重复自动检测功能 适配版本:3x以上 2023-04-26 20:08:59 编号:50 #2023-04-26 20:08:29 299.00 pbootcms留言表单手机短信验证(阿里云短信) <··· 编号:49 #2023-04-26 20:08:00 299.00 PbootCMS后台TAG标签管理插件 适配版本:3x以上 2023-04-26 20:08:00 查看更多 建站教程 > 1php里error_reporting() 的分析 2正则 的 分组语法(又叫 捕获 和 断言/零宽断言 ) 3百度统计免登陆查看数据的方法 4点击网页上QQ提示对方QQ在线状态”服务尚未启用 5仿站专家告诉你,做网站有哪些账号密码需要管理? 6未备案域名怎么使用国内cdn(七牛云)加速网站? 7没买虚拟主机或云服务器可以在阿里云备案吗? 8FlashFXP连接宝塔ftp提示“列表错误”怎么办 9解决网站在宝塔面板偶尔出现CPU100%的情况 10用PbootCMS做个网站要多少钱? 实用代码 > 1pbootcms在线升级后伪静态分页url变成?page=xx问题 2PbootCMS常用if判断语句 3pbootcms提示:登录失败:表单提交校验失败,请刷新后重试! 4西部数码虚拟主机上pbootcms使用注意(邮件通知、非法字符) 5pbootcms新增扩展标签实现单独手机端详情判断 6pbootcms3.2.2导入sql失败报错问题处理 7PC网站缩小在手机上显示的一条代码 8百度地图API调用时在网站上不显示原因 9jquery点击按钮复制内容代码(兼容PC、手机端) 10带/index.php的主域名301重定向到默认主域名 cms教程 > 1巧用伪静态让虚拟主机支持域名绑定到子目录 2pbootcms授权码免费获取(通过小程序获取) 3适合PbootCMS的阿里云短信发送类 4pbootcms列表页排序切换(时间/浏览量/推荐...) 5pbootcms去除ueditor编辑器上传图片自动添加的title和alt属性 6pbootcms后台编辑器插入视频无法播放怎么办 7pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 8pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 9pbootcms基本使用教程(快速入门视频) 10如何将pbootcms手机网页封装成微信小程序 网站seo > 1pbootcms2.0针对SEO优化之扁平化目录结构 2网站文章如何打造seo高质量伪原创? 3新站SEO优化该从何入手 4百度统计中出现垃圾网站被恶意刷关键词的解决办法 5网站被镜像的影响及解决方案 6百度快照显示网站图片或者公司LOGO怎么做? 72023年了为什么还有人做SEO? 8企业建站要注意这些细节,流量翻倍不是梦 9网站快排套路到底有多深? 10网站SEO文章双标题是什么?SEO双标题作用 不要把时间用来造轮子,这里有的你拿走,保留精力用来创造! 目前为止共有 2803 位优秀的站长加入! 立即加入vip 百元建站活动 QQ 客服在线 周一至周日 11:00-23:00 PBHTML团队为您服务 点击添加好友后咨询 微信 扫一扫添加客服微信 Q群 登录 注册 我已阅读并同意 《用户注册协议》 活动公告 本站全新品牌升级已于2022.12.28正式上线!限时特惠活动:终身VIP原价298元,现价198元!活动日期:2022.12.28 ~ 2023.12.30终身VIP特权将会逐步增加,早加入早受益!我们的目标:做最干净的模板,无内置广告链接。
编号:111 #2023-04-26 22:02:38 299.00 pbootcms定制url服务包 针对各种老网站转pbootcms··· 编号:110 #2023-04-26 22:01:10 299.00 pbootcms文章内容分页(基础版) &··· 编号:109 #2023-04-26 22:00:15 299.00 pbootcms提取content字段到独立表ay_content_data 针对pbootcms站点数据达到5W以上,提取content字段到新··· 编号:108 #2023-04-26 21:59:20 299.00 pbootcms多语言目录名方式切换 <··· 编号:52 #2023-04-26 20:09:28 299.00 pbootcms增加关联扩展字段 适配版本:3x以上 2023-04-26 20:09:28 编号:51 #2023-04-26 20:08:59 299.00 pbootcms标题重复自动检测功能 适配版本:3x以上 2023-04-26 20:08:59 编号:50 #2023-04-26 20:08:29 299.00 pbootcms留言表单手机短信验证(阿里云短信) <··· 编号:49 #2023-04-26 20:08:00 299.00 PbootCMS后台TAG标签管理插件 适配版本:3x以上 2023-04-26 20:08:00 查看更多 建站教程 > 1php里error_reporting() 的分析 2正则 的 分组语法(又叫 捕获 和 断言/零宽断言 ) 3百度统计免登陆查看数据的方法 4点击网页上QQ提示对方QQ在线状态”服务尚未启用 5仿站专家告诉你,做网站有哪些账号密码需要管理? 6未备案域名怎么使用国内cdn(七牛云)加速网站? 7没买虚拟主机或云服务器可以在阿里云备案吗? 8FlashFXP连接宝塔ftp提示“列表错误”怎么办 9解决网站在宝塔面板偶尔出现CPU100%的情况 10用PbootCMS做个网站要多少钱? 实用代码 > 1pbootcms在线升级后伪静态分页url变成?page=xx问题 2PbootCMS常用if判断语句 3pbootcms提示:登录失败:表单提交校验失败,请刷新后重试! 4西部数码虚拟主机上pbootcms使用注意(邮件通知、非法字符) 5pbootcms新增扩展标签实现单独手机端详情判断 6pbootcms3.2.2导入sql失败报错问题处理 7PC网站缩小在手机上显示的一条代码 8百度地图API调用时在网站上不显示原因 9jquery点击按钮复制内容代码(兼容PC、手机端) 10带/index.php的主域名301重定向到默认主域名 cms教程 > 1巧用伪静态让虚拟主机支持域名绑定到子目录 2pbootcms授权码免费获取(通过小程序获取) 3适合PbootCMS的阿里云短信发送类 4pbootcms列表页排序切换(时间/浏览量/推荐...) 5pbootcms去除ueditor编辑器上传图片自动添加的title和alt属性 6pbootcms后台编辑器插入视频无法播放怎么办 7pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 8pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 9pbootcms基本使用教程(快速入门视频) 10如何将pbootcms手机网页封装成微信小程序 网站seo > 1pbootcms2.0针对SEO优化之扁平化目录结构 2网站文章如何打造seo高质量伪原创? 3新站SEO优化该从何入手 4百度统计中出现垃圾网站被恶意刷关键词的解决办法 5网站被镜像的影响及解决方案 6百度快照显示网站图片或者公司LOGO怎么做? 72023年了为什么还有人做SEO? 8企业建站要注意这些细节,流量翻倍不是梦 9网站快排套路到底有多深? 10网站SEO文章双标题是什么?SEO双标题作用 不要把时间用来造轮子,这里有的你拿走,保留精力用来创造! 目前为止共有 2803 位优秀的站长加入! 立即加入vip 百元建站活动 QQ 客服在线 周一至周日 11:00-23:00 PBHTML团队为您服务 点击添加好友后咨询 微信 扫一扫添加客服微信 Q群 登录 注册 我已阅读并同意 《用户注册协议》 活动公告 本站全新品牌升级已于2022.12.28正式上线!限时特惠活动:终身VIP原价298元,现价198元!活动日期:2022.12.28 ~ 2023.12.30终身VIP特权将会逐步增加,早加入早受益!我们的目标:做最干净的模板,无内置广告链接。
编号:110 #2023-04-26 22:01:10 299.00 pbootcms文章内容分页(基础版) &··· 编号:109 #2023-04-26 22:00:15 299.00 pbootcms提取content字段到独立表ay_content_data 针对pbootcms站点数据达到5W以上,提取content字段到新··· 编号:108 #2023-04-26 21:59:20 299.00 pbootcms多语言目录名方式切换 <··· 编号:52 #2023-04-26 20:09:28 299.00 pbootcms增加关联扩展字段 适配版本:3x以上 2023-04-26 20:09:28 编号:51 #2023-04-26 20:08:59 299.00 pbootcms标题重复自动检测功能 适配版本:3x以上 2023-04-26 20:08:59 编号:50 #2023-04-26 20:08:29 299.00 pbootcms留言表单手机短信验证(阿里云短信) <··· 编号:49 #2023-04-26 20:08:00 299.00 PbootCMS后台TAG标签管理插件 适配版本:3x以上 2023-04-26 20:08:00 查看更多 建站教程 > 1php里error_reporting() 的分析 2正则 的 分组语法(又叫 捕获 和 断言/零宽断言 ) 3百度统计免登陆查看数据的方法 4点击网页上QQ提示对方QQ在线状态”服务尚未启用 5仿站专家告诉你,做网站有哪些账号密码需要管理? 6未备案域名怎么使用国内cdn(七牛云)加速网站? 7没买虚拟主机或云服务器可以在阿里云备案吗? 8FlashFXP连接宝塔ftp提示“列表错误”怎么办 9解决网站在宝塔面板偶尔出现CPU100%的情况 10用PbootCMS做个网站要多少钱? 实用代码 > 1pbootcms在线升级后伪静态分页url变成?page=xx问题 2PbootCMS常用if判断语句 3pbootcms提示:登录失败:表单提交校验失败,请刷新后重试! 4西部数码虚拟主机上pbootcms使用注意(邮件通知、非法字符) 5pbootcms新增扩展标签实现单独手机端详情判断 6pbootcms3.2.2导入sql失败报错问题处理 7PC网站缩小在手机上显示的一条代码 8百度地图API调用时在网站上不显示原因 9jquery点击按钮复制内容代码(兼容PC、手机端) 10带/index.php的主域名301重定向到默认主域名 cms教程 > 1巧用伪静态让虚拟主机支持域名绑定到子目录 2pbootcms授权码免费获取(通过小程序获取) 3适合PbootCMS的阿里云短信发送类 4pbootcms列表页排序切换(时间/浏览量/推荐...) 5pbootcms去除ueditor编辑器上传图片自动添加的title和alt属性 6pbootcms后台编辑器插入视频无法播放怎么办 7pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 8pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 9pbootcms基本使用教程(快速入门视频) 10如何将pbootcms手机网页封装成微信小程序 网站seo > 1pbootcms2.0针对SEO优化之扁平化目录结构 2网站文章如何打造seo高质量伪原创? 3新站SEO优化该从何入手 4百度统计中出现垃圾网站被恶意刷关键词的解决办法 5网站被镜像的影响及解决方案 6百度快照显示网站图片或者公司LOGO怎么做? 72023年了为什么还有人做SEO? 8企业建站要注意这些细节,流量翻倍不是梦 9网站快排套路到底有多深? 10网站SEO文章双标题是什么?SEO双标题作用 不要把时间用来造轮子,这里有的你拿走,保留精力用来创造! 目前为止共有 2803 位优秀的站长加入! 立即加入vip 百元建站活动 QQ 客服在线 周一至周日 11:00-23:00 PBHTML团队为您服务 点击添加好友后咨询 微信 扫一扫添加客服微信 Q群 登录 注册 我已阅读并同意 《用户注册协议》 活动公告 本站全新品牌升级已于2022.12.28正式上线!限时特惠活动:终身VIP原价298元,现价198元!活动日期:2022.12.28 ~ 2023.12.30终身VIP特权将会逐步增加,早加入早受益!我们的目标:做最干净的模板,无内置广告链接。
编号:109 #2023-04-26 22:00:15 299.00 pbootcms提取content字段到独立表ay_content_data 针对pbootcms站点数据达到5W以上,提取content字段到新··· 编号:108 #2023-04-26 21:59:20 299.00 pbootcms多语言目录名方式切换 <··· 编号:52 #2023-04-26 20:09:28 299.00 pbootcms增加关联扩展字段 适配版本:3x以上 2023-04-26 20:09:28 编号:51 #2023-04-26 20:08:59 299.00 pbootcms标题重复自动检测功能 适配版本:3x以上 2023-04-26 20:08:59 编号:50 #2023-04-26 20:08:29 299.00 pbootcms留言表单手机短信验证(阿里云短信) <··· 编号:49 #2023-04-26 20:08:00 299.00 PbootCMS后台TAG标签管理插件 适配版本:3x以上 2023-04-26 20:08:00 查看更多 建站教程 > 1php里error_reporting() 的分析 2正则 的 分组语法(又叫 捕获 和 断言/零宽断言 ) 3百度统计免登陆查看数据的方法 4点击网页上QQ提示对方QQ在线状态”服务尚未启用 5仿站专家告诉你,做网站有哪些账号密码需要管理? 6未备案域名怎么使用国内cdn(七牛云)加速网站? 7没买虚拟主机或云服务器可以在阿里云备案吗? 8FlashFXP连接宝塔ftp提示“列表错误”怎么办 9解决网站在宝塔面板偶尔出现CPU100%的情况 10用PbootCMS做个网站要多少钱? 实用代码 > 1pbootcms在线升级后伪静态分页url变成?page=xx问题 2PbootCMS常用if判断语句 3pbootcms提示:登录失败:表单提交校验失败,请刷新后重试! 4西部数码虚拟主机上pbootcms使用注意(邮件通知、非法字符) 5pbootcms新增扩展标签实现单独手机端详情判断 6pbootcms3.2.2导入sql失败报错问题处理 7PC网站缩小在手机上显示的一条代码 8百度地图API调用时在网站上不显示原因 9jquery点击按钮复制内容代码(兼容PC、手机端) 10带/index.php的主域名301重定向到默认主域名 cms教程 > 1巧用伪静态让虚拟主机支持域名绑定到子目录 2pbootcms授权码免费获取(通过小程序获取) 3适合PbootCMS的阿里云短信发送类 4pbootcms列表页排序切换(时间/浏览量/推荐...) 5pbootcms去除ueditor编辑器上传图片自动添加的title和alt属性 6pbootcms后台编辑器插入视频无法播放怎么办 7pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 8pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 9pbootcms基本使用教程(快速入门视频) 10如何将pbootcms手机网页封装成微信小程序 网站seo > 1pbootcms2.0针对SEO优化之扁平化目录结构 2网站文章如何打造seo高质量伪原创? 3新站SEO优化该从何入手 4百度统计中出现垃圾网站被恶意刷关键词的解决办法 5网站被镜像的影响及解决方案 6百度快照显示网站图片或者公司LOGO怎么做? 72023年了为什么还有人做SEO? 8企业建站要注意这些细节,流量翻倍不是梦 9网站快排套路到底有多深? 10网站SEO文章双标题是什么?SEO双标题作用 不要把时间用来造轮子,这里有的你拿走,保留精力用来创造! 目前为止共有 2803 位优秀的站长加入! 立即加入vip 百元建站活动 QQ 客服在线 周一至周日 11:00-23:00 PBHTML团队为您服务 点击添加好友后咨询 微信 扫一扫添加客服微信 Q群 登录 注册 我已阅读并同意 《用户注册协议》 活动公告 本站全新品牌升级已于2022.12.28正式上线!限时特惠活动:终身VIP原价298元,现价198元!活动日期:2022.12.28 ~ 2023.12.30终身VIP特权将会逐步增加,早加入早受益!我们的目标:做最干净的模板,无内置广告链接。
编号:108 #2023-04-26 21:59:20 299.00 pbootcms多语言目录名方式切换 <··· 编号:52 #2023-04-26 20:09:28 299.00 pbootcms增加关联扩展字段 适配版本:3x以上 2023-04-26 20:09:28 编号:51 #2023-04-26 20:08:59 299.00 pbootcms标题重复自动检测功能 适配版本:3x以上 2023-04-26 20:08:59 编号:50 #2023-04-26 20:08:29 299.00 pbootcms留言表单手机短信验证(阿里云短信) <··· 编号:49 #2023-04-26 20:08:00 299.00 PbootCMS后台TAG标签管理插件 适配版本:3x以上 2023-04-26 20:08:00 查看更多 建站教程 > 1php里error_reporting() 的分析 2正则 的 分组语法(又叫 捕获 和 断言/零宽断言 ) 3百度统计免登陆查看数据的方法 4点击网页上QQ提示对方QQ在线状态”服务尚未启用 5仿站专家告诉你,做网站有哪些账号密码需要管理? 6未备案域名怎么使用国内cdn(七牛云)加速网站? 7没买虚拟主机或云服务器可以在阿里云备案吗? 8FlashFXP连接宝塔ftp提示“列表错误”怎么办 9解决网站在宝塔面板偶尔出现CPU100%的情况 10用PbootCMS做个网站要多少钱? 实用代码 > 1pbootcms在线升级后伪静态分页url变成?page=xx问题 2PbootCMS常用if判断语句 3pbootcms提示:登录失败:表单提交校验失败,请刷新后重试! 4西部数码虚拟主机上pbootcms使用注意(邮件通知、非法字符) 5pbootcms新增扩展标签实现单独手机端详情判断 6pbootcms3.2.2导入sql失败报错问题处理 7PC网站缩小在手机上显示的一条代码 8百度地图API调用时在网站上不显示原因 9jquery点击按钮复制内容代码(兼容PC、手机端) 10带/index.php的主域名301重定向到默认主域名 cms教程 > 1巧用伪静态让虚拟主机支持域名绑定到子目录 2pbootcms授权码免费获取(通过小程序获取) 3适合PbootCMS的阿里云短信发送类 4pbootcms列表页排序切换(时间/浏览量/推荐...) 5pbootcms去除ueditor编辑器上传图片自动添加的title和alt属性 6pbootcms后台编辑器插入视频无法播放怎么办 7pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 8pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 9pbootcms基本使用教程(快速入门视频) 10如何将pbootcms手机网页封装成微信小程序 网站seo > 1pbootcms2.0针对SEO优化之扁平化目录结构 2网站文章如何打造seo高质量伪原创? 3新站SEO优化该从何入手 4百度统计中出现垃圾网站被恶意刷关键词的解决办法 5网站被镜像的影响及解决方案 6百度快照显示网站图片或者公司LOGO怎么做? 72023年了为什么还有人做SEO? 8企业建站要注意这些细节,流量翻倍不是梦 9网站快排套路到底有多深? 10网站SEO文章双标题是什么?SEO双标题作用 不要把时间用来造轮子,这里有的你拿走,保留精力用来创造! 目前为止共有 2803 位优秀的站长加入! 立即加入vip 百元建站活动 QQ 客服在线 周一至周日 11:00-23:00 PBHTML团队为您服务 点击添加好友后咨询 微信 扫一扫添加客服微信 Q群 登录 注册 我已阅读并同意 《用户注册协议》 活动公告 本站全新品牌升级已于2022.12.28正式上线!限时特惠活动:终身VIP原价298元,现价198元!活动日期:2022.12.28 ~ 2023.12.30终身VIP特权将会逐步增加,早加入早受益!我们的目标:做最干净的模板,无内置广告链接。
编号:52 #2023-04-26 20:09:28 299.00 pbootcms增加关联扩展字段 适配版本:3x以上 2023-04-26 20:09:28 编号:51 #2023-04-26 20:08:59 299.00 pbootcms标题重复自动检测功能 适配版本:3x以上 2023-04-26 20:08:59 编号:50 #2023-04-26 20:08:29 299.00 pbootcms留言表单手机短信验证(阿里云短信) <··· 编号:49 #2023-04-26 20:08:00 299.00 PbootCMS后台TAG标签管理插件 适配版本:3x以上 2023-04-26 20:08:00 查看更多 建站教程 > 1php里error_reporting() 的分析 2正则 的 分组语法(又叫 捕获 和 断言/零宽断言 ) 3百度统计免登陆查看数据的方法 4点击网页上QQ提示对方QQ在线状态”服务尚未启用 5仿站专家告诉你,做网站有哪些账号密码需要管理? 6未备案域名怎么使用国内cdn(七牛云)加速网站? 7没买虚拟主机或云服务器可以在阿里云备案吗? 8FlashFXP连接宝塔ftp提示“列表错误”怎么办 9解决网站在宝塔面板偶尔出现CPU100%的情况 10用PbootCMS做个网站要多少钱? 实用代码 > 1pbootcms在线升级后伪静态分页url变成?page=xx问题 2PbootCMS常用if判断语句 3pbootcms提示:登录失败:表单提交校验失败,请刷新后重试! 4西部数码虚拟主机上pbootcms使用注意(邮件通知、非法字符) 5pbootcms新增扩展标签实现单独手机端详情判断 6pbootcms3.2.2导入sql失败报错问题处理 7PC网站缩小在手机上显示的一条代码 8百度地图API调用时在网站上不显示原因 9jquery点击按钮复制内容代码(兼容PC、手机端) 10带/index.php的主域名301重定向到默认主域名 cms教程 > 1巧用伪静态让虚拟主机支持域名绑定到子目录 2pbootcms授权码免费获取(通过小程序获取) 3适合PbootCMS的阿里云短信发送类 4pbootcms列表页排序切换(时间/浏览量/推荐...) 5pbootcms去除ueditor编辑器上传图片自动添加的title和alt属性 6pbootcms后台编辑器插入视频无法播放怎么办 7pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 8pbootcms网站修改CSS样式后自动更新缓存(扩展标签实现自动增加版本号) 9pbootcms基本使用教程(快速入门视频) 10如何将pbootcms手机网页封装成微信小程序 网站seo > 1pbootcms2.0针对SEO优化之扁平化目录结构 2网站文章如何打造seo高质量伪原创? 3新站SEO优化该从何入手 4百度统计中出现垃圾网站被恶意刷关键词的解决办法 5网站被镜像的影响及解决方案 6百度快照显示网站图片或者公司LOGO怎么做? 72023年了为什么还有人做SEO? 8企业建站要注意这些细节,流量翻倍不是梦 9网站快排套路到底有多深? 10网站SEO文章双标题是什么?SEO双标题作用
编号:51 #2023-04-26 20:08:59 299.00 pbootcms标题重复自动检测功能 适配版本:3x以上 2023-04-26 20:08:59 编号:50 #2023-04-26 20:08:29 299.00 pbootcms留言表单手机短信验证(阿里云短信) <··· 编号:49 #2023-04-26 20:08:00 299.00 PbootCMS后台TAG标签管理插件 适配版本:3x以上 2023-04-26 20:08:00 查看更多
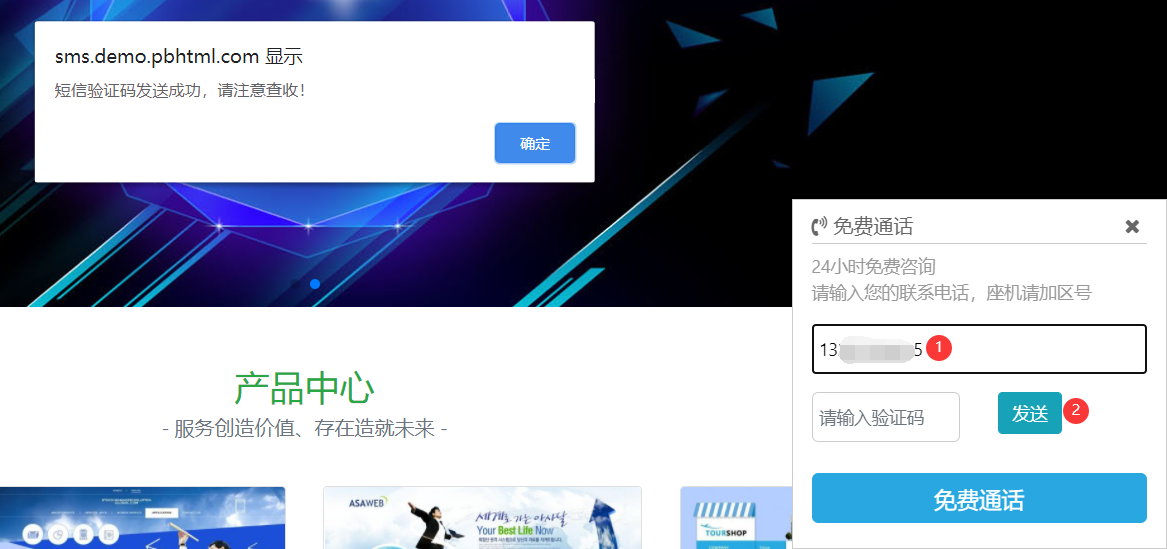
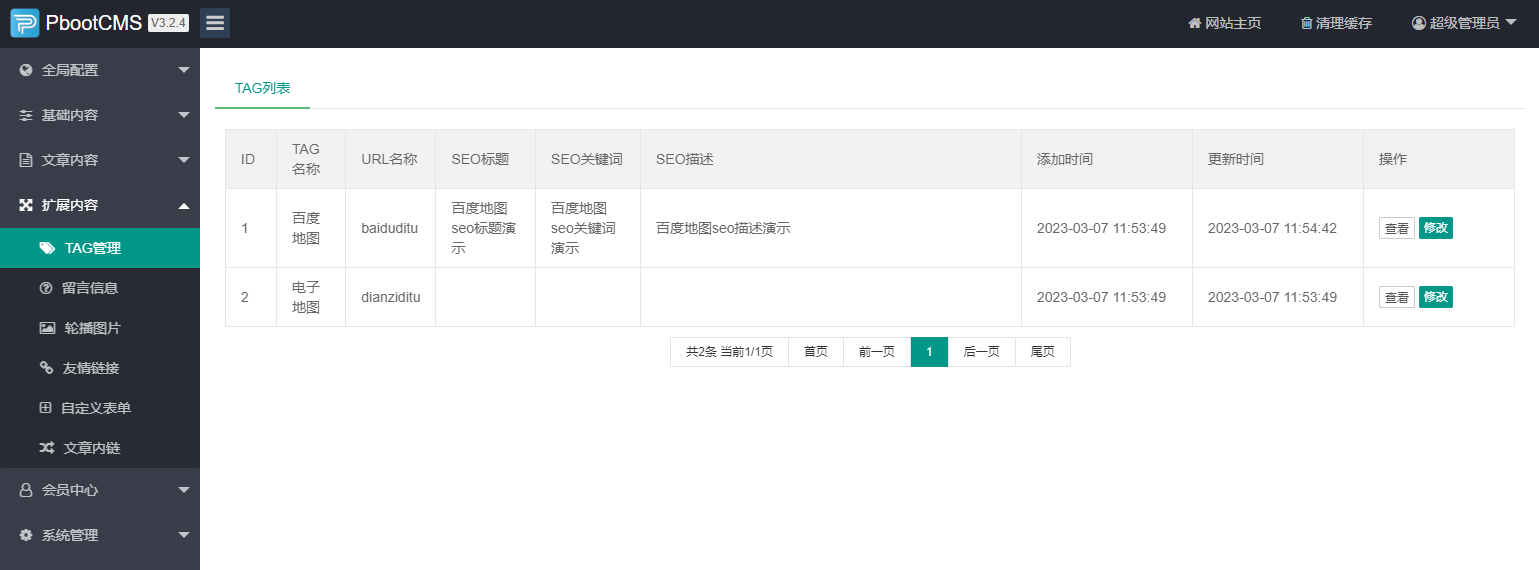
编号:50 #2023-04-26 20:08:29 299.00 pbootcms留言表单手机短信验证(阿里云短信) <··· 编号:49 #2023-04-26 20:08:00 299.00 PbootCMS后台TAG标签管理插件 适配版本:3x以上 2023-04-26 20:08:00 查看更多